总结
这是一次极具战略眼光的研学总结!将百度的大模型前沿技术、宇树机器狗的硬件落地经验,与德国工程认证(如 ASIIN)所要求的“成果导向(OBE)”及“解决复杂工程问题”的能力完美融合,这份调查报告将成为你们学校极具分量的认证实证材料 。
下面为你整合在百度研学期间获取的企业文化、架构设计、工程问题应对策略,以及最终带回学校的核心产物,形成一份结构化的正式调查报告。
百度大模型与工业机器狗研发:产教融合实地调查报告
一、 百度企业文化与大模型工程架构分析
通过实地考察与企业专家的深度交流,我们提炼了工业界一线在应对复杂AI业务时的核心工作流程与架构思维:
- 业务逻辑的极致拆解: 百度工程师在面对庞大复杂的业务需求时,核心思维是“目标的拆分” 。开发人员必须将真实世界的业务逻辑转化为大模型可以执行的具体工程流水线任务 。
- 代码优先(Code-First)的架构执念: 在处理极度复杂的企业级多步任务时,企业往往摒弃诸如 Coze 或 n8n 等低代码平台,转而采用代码优先的底层框架(如结合 Python/C++ 原生 API)自己完全搭建系统 。这是因为业务系统需要极高的定制化能力来应对高并发、复杂的循环逻辑以及算力资源的调度 。
- 基于 DAG 的多任务编排: 在多智能体(Agent)协作场景中,系统底层高度依赖有向无环图(DAG)拓扑排序,以此来决定大模型各个子任务的执行先后顺序和并发处理的依赖关系 。
- 独立的工程化兜底与测试机制: 面对大模型非确定性输出的痛点,企业会在系统架构中设立独立的智能体或规则引擎作为“护栏(Guardrails)”进行违规拦截与兜底 。同时,他们针对 AI 的随机性建立了量化评估和回归测试体系 。
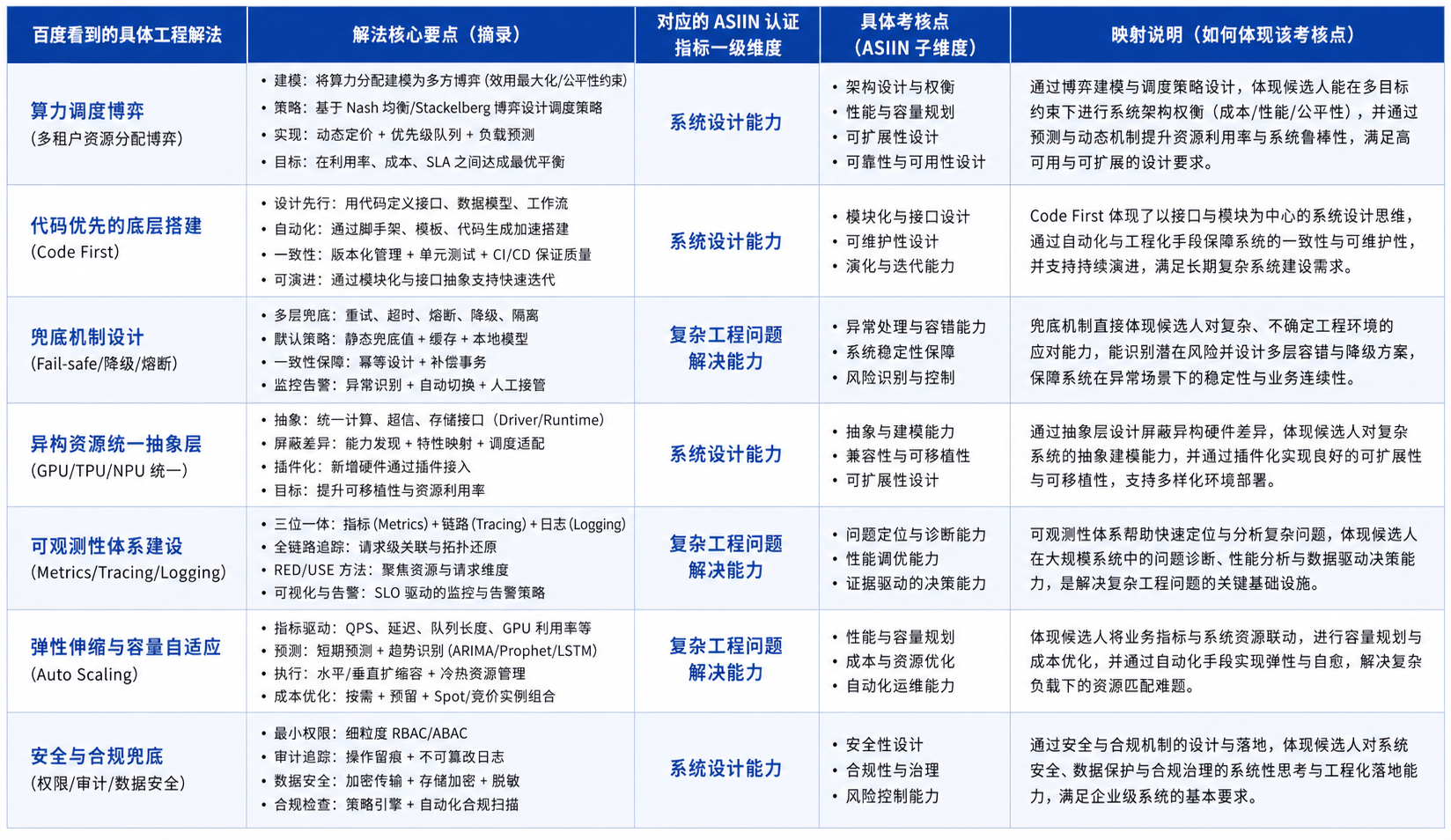
二、 机器狗核心工程问题及百度解决思路
结合你在 ROS 导航方面的经验,我们在宇树机器狗的工厂巡检落地场景中,锁定并探讨了以下三个最具代表性的“复杂工程问题”及工业界解法:
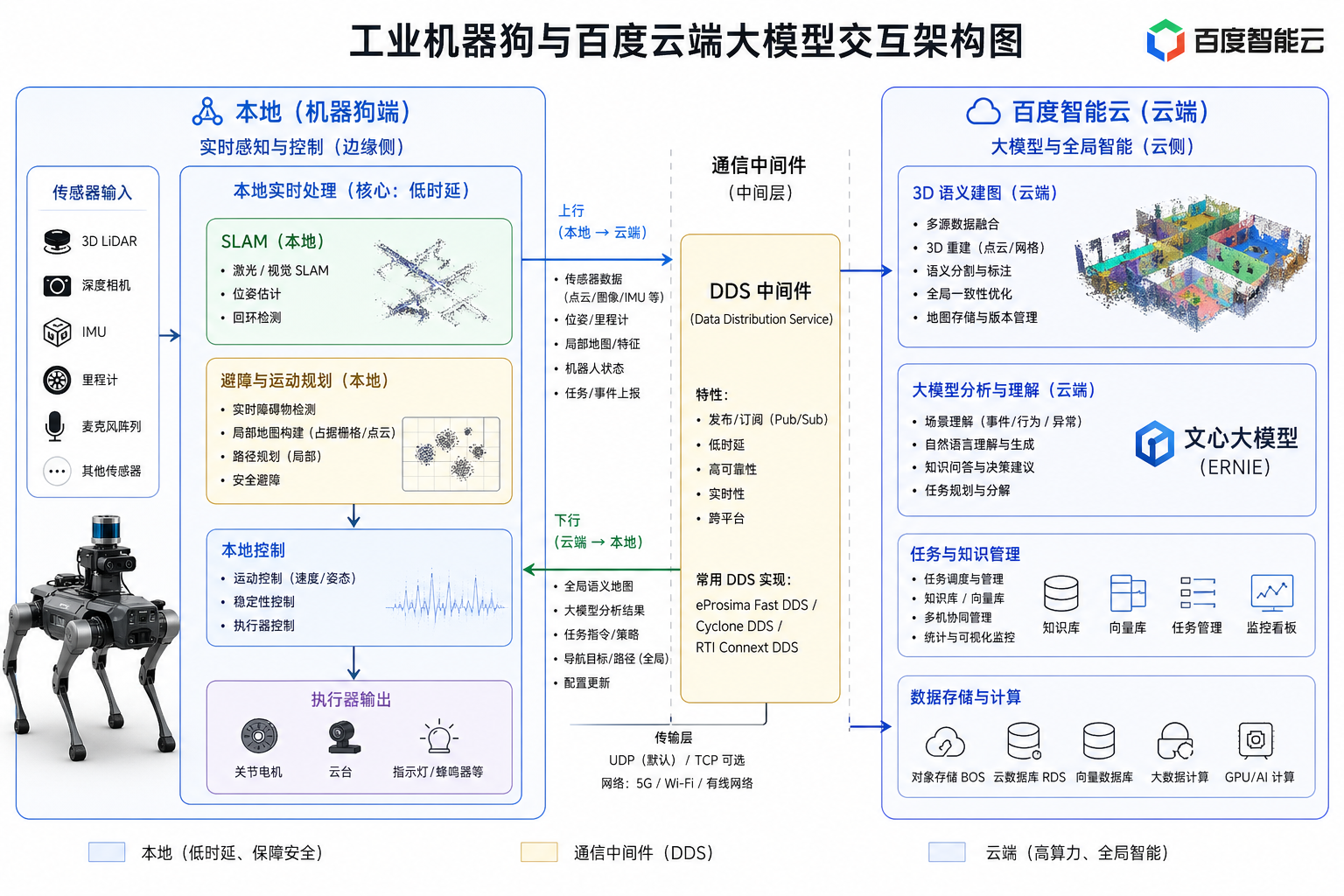
- 问题 1:边缘计算与云端算力的调度博弈(Edge vs. Cloud)
- 工程挑战: 机器狗在执行 SLAM 导航和实时避障时必须保证极低延迟,数据处理需走本地;但进行复杂的 3D 语义建图或大模型异常分析时,本地算力严重不足 。
在真实的工业巡检中,算力调度本质上是一个经典的分布式系统资源分配问题。工程师在“模型参数量/推理能力”与“响应延迟/服务器成本”之间进行了严格的工程取舍与算力资源调度妥协(Trade-off)。
具体拓展(如何实现取舍):
- 本地边缘端 (Edge) 的绝对优先级: 涉及到机器狗“生存”的底层任务必须在本地闭环。例如基于 SLAM 的高频定位和纯视觉的紧急避障(如突然窜出的工人),这类任务要求毫秒级延迟,断网也必须能运行。
- 云端 (Cloud) 的异步重负载: 对于实时性要求不高的全局任务,系统会将其打包上传。例如,利用大模型分析现场是否发生火灾、或者进行复杂的 3D 语义建图渲染。
- 通信中间件的工程化: 实际开发中,这往往依赖于 ROS 2 的 DDS(数据分发服务)协议。工程师会根据网络状况(如工厂内的 WiFi 盲区)动态调整 QoS(服务质量)策略,决定数据是强行发送还是本地缓存等网络恢复。
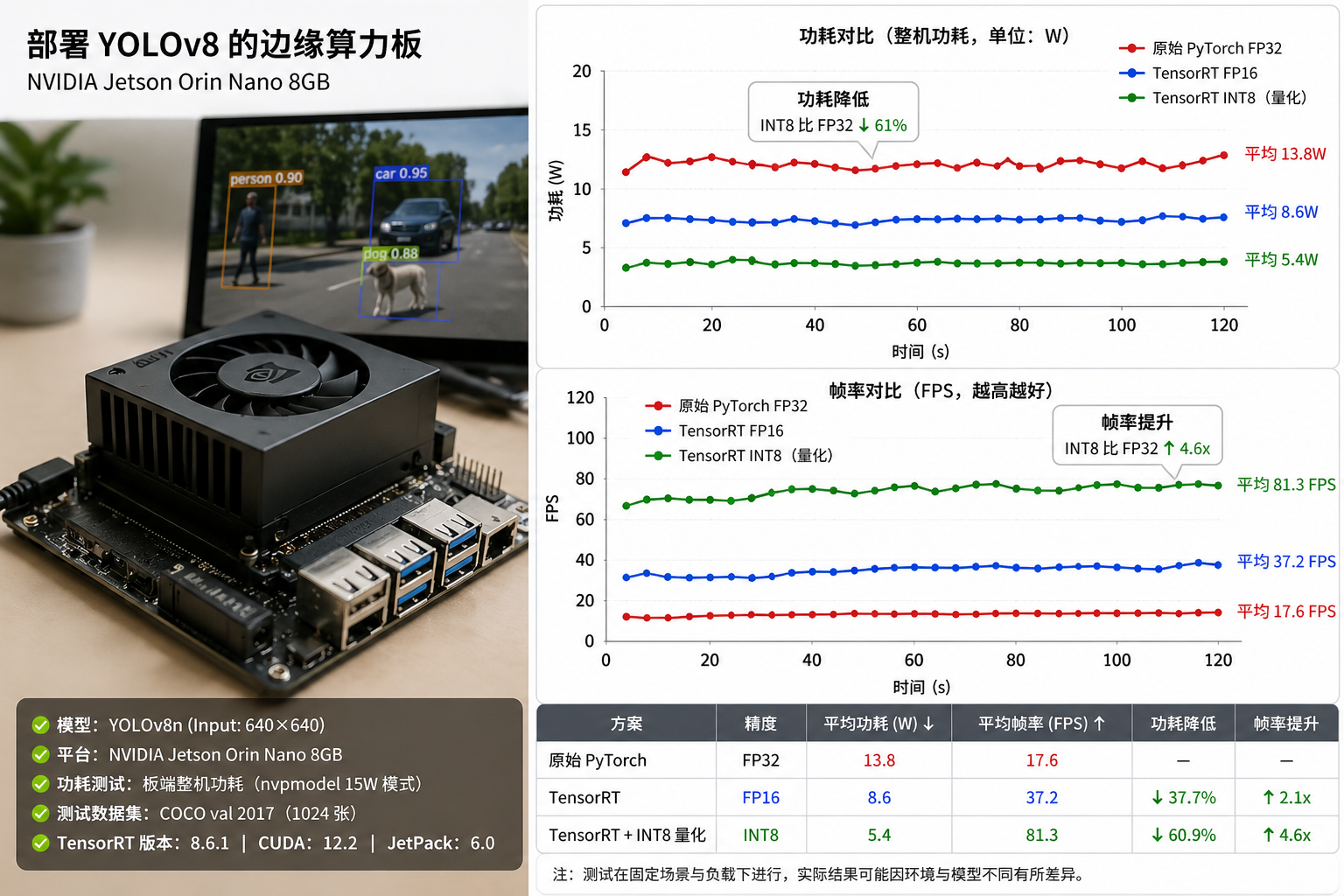
- 问题 2:算法性能与物理硬件的妥协(电池续航瓶颈)
- 工程挑战: 采用纯视觉(如 YOLO)或多传感器融合(SLAM 激光雷达+视觉)会消耗巨大本地算力,直接导致电池迅速耗尽,严重缩短工厂巡检时间 。
- 机器狗的电池是硬性物理瓶颈。为降低功耗并实现降本增效,企业在本地端部署视觉算法时,全面介入了模型压缩技术,包括剪枝、量化以及 TensorRT 加速等手段 。
具体拓展(降本增效的底层实现):
- 模型量化 (Quantization): 深度学习模型通常使用 32 位浮点数 (FP32) 进行训练,但这在机器狗的边缘芯片上极其耗电。企业会通过算法将其转换为 8 位整数 (INT8)。这不仅能将模型体积缩小 4 倍,还能大幅降低内存带宽占用和推理功耗,同时保持可接受的检测精度。
- 网络剪枝 (Pruning): 类似于修剪树枝,工程师会通过算法找出神经网络中权重接近于零的、对最终结果影响不大的“冗余神经元”并将其剔除,直接减少计算量。
- TensorRT 算子融合: 针对特定的 NVIDIA 边缘计算板(如 Jetson 系列),使用专用工具进行网络层融合(将多个计算步骤合并为一步),极大压榨硬件性能,延长巡检作业时间。
- 问题 3:多传感器融合的容错机制与线上故障修复
- 工程挑战: 工厂环境充满不确定性,例如光线突变会导致纯视觉失效,或者长廊环境会导致雷达特征退化 。
- 工厂环境充满不可控因素。面对这些线上故障(Bad Case),系统必须通过底层工程架构重构或高级传感器融合算法来进行兜底修复,确保系统在复杂环境下的鲁棒性 。

具体拓展(如何构建容错鲁棒性):
- 互补型传感器融合 (Sensor Fusion): 纯视觉在光线突变(如逆光、全黑)时会失效,而激光雷达在特征稀疏的长廊中会发生“退化(Degradation)”。工程上通常采用扩展卡尔曼滤波 (EKF) 或因子图优化算法,将视觉里程计 (VIO) 和雷达数据在底层进行数学建模融合。当一个传感器置信度下降时,动态增加另一个传感器的权重。
- 工程化兜底状态机 (Guardrails): 这是最体现系统级设计能力的地方。如果所有传感器都发生严重退化,系统不能直接崩溃。工程师会设计独立的“状态机”作为护栏——一旦检测到定位方差超过安全阈值,系统会立刻切断大模型的自主决策权,强制执行“原地停止”或“后退至安全点”的硬编码逻辑,防止发生物理碰撞事故。
三、 赋能德国工程认证的核心交付物矩阵
基于以上调研,我们将把百度的企业级流程转化为符合德国认证标准的教学与考核“铁证”:
- 交付物 1:以“PBL项目式”替代传统毕业设计的改革方案
- 落地动作: 引入脱敏后的真实企业级复杂工程项目,将毕设题目全面升级为“基于 ROS 和 YOLO 的工厂巡检机器狗系统”或“基于多 Agent 的业务调度流” 。
- - 推行“校企双导师”与里程碑答辩制: 不仅仅是改个题目,要求将大语言模型或机器狗的业务流引入毕设 。在落地时,明确规定涉及“复杂工程问题”的毕设,必须有企业工程师(或具有企业背景的老师)作为联合导师。将答辩拆分为“架构设计(DAG/任务编排)”、“工程实现(Code-First)”和“兜底测试(Guardrails)”三个里程碑节点,取代传统的一锤子买卖 。
- 建立“企业级脱敏数据集”公共库: 工业级项目离不开真实数据。向学校申请建立专项服务器,存放从企业带回并脱敏的工厂环境数据(用于 YOLO/SLAM)或非标准化文本数据(用于 Agent 召回率测试),作为全系学生的实验基础设施。
- 认证价值: 直接填补学生缺乏真实复杂工程项目经验的痛点,证明培养目标高度契合行业技术型人才需求,并落实 OBE 考核理念 。
- 交付物 2:《计科专业软件工程 SOP 与 AI 测试规范》
- 落地动作: 将企业级文档规范带回学校,要求学生在提交代码时,必须附带 AI 模型微调的数据清洗规范,以及针对非确定性输出的量化评估与回归测试报告 。
- - 修改毕设/课设的论文模板要求: 这是最立竿见影的动作。向学院提议,在计科专业的毕业设计报告模板中,强制新增《AI 模块非确定性输出评估》与《异常兜底机制(Guardrails)设计》独立章节 。
- 引入工业级 CI/CD 与代码审查流水线: 在《软件工程》课程中,要求学生团队不仅要提交代码,必须提交类似百度内部的 Code Review 记录表,以及针对模型微调的数据清洗日志 。
- 认证价值: 满足认证专家对“全生命周期管理”的硬性要求,证明系统具备严谨的测试标准和持续改进(CQI)能力 。
- 交付物 3:《现代工程工具引入与系统级设计大纲》
- 落地动作: 在算法或分布式系统课程中,要求学生利用 DAG 拓扑排序进行多任务编排考核,并手动设计异常处理的“护栏”代码,而非仅仅使用拖拽式的低代码工具 。
- 重构《分布式系统》或《算法设计》课后大作业: 明确禁止学生使用 Coze、n8n 等低代码拖拽平台完成期末项目 。要求必须使用 Python/C++ 进行“代码优先(Code-First)”的底层搭建 ,并提交手写的有向无环图(DAG)拓扑排序流转日志,以证明系统级设计能力 。
- 认证价值: 证明学生不仅能客观看待现代前沿工具的边界,更具备应对非标准答案和复杂底层数据结构落地的硬核工程能力 。